have any of you used a fuzzer for debugging? what specific fuzzing tool did you use?
@b0rk Not a fuzzer, per se, but I have used hypothesis in Python testing, and it definitely finds bugs and edge cases I wasn't considering when coding or writing test cases...
@b0rk I once used AFL very successfully for finding weird edge case bugs in some input file parsing code that I never would have found on my own
@b0rk Some years ago I fuzzed a small C project using https://lcamtuf.coredump.cx/afl/. Loved it. It needed just a couple of seconds to find some glaring arithmetic underflows in my offset math.
@b0rk never for debugging as in "I know there is a bug, I have to fix that". But often to find bugs in the first place.
@b0rk always wrote my own - you want to generate a lot of 'near correct' and 'should be correct but your a dumbass' and raw random feeds give you lots of <monkeys writing Shakespeare>
(also I am not sure there were fuzzing tools then neither)
@b0rk i used quickcheck in clojure to test some compiler stuff a while back! it was effective but not worth the effort of maintaining it for my particular use case in the end.
@b0rk python hypothesis. Give it python code and it generates unit tests that feed every possible sort of data into the functions to see if they blow up or not.
@b0rk @dcrosta Also in the property-based/generative testing camp: I've used JS fast-check on an XState state machine before realizing XState has its own model based testing library. 🤦♂️ It was a fun exercise though...
https://github.com/dubzzz/fast-check
https://xstate.js.org/docs/packages/xstate-test/#quick-start
also, I'm trying to make a list of data formatting tools (like hexdump, xxd, jq, and graphviz) -- I feel like there are some I'm missing
@b0rk I'm not sure how close this is to what you're aiming for, but jc (https://kellyjonbrazil.github.io/jc/) might fit the bill: it converts a *huge* number of bespoke formats to JSON to allow processing with jq/nu/etc.
@b0rk honestly I throw LibreCalc/Excel in that pile too. with careful delimiting and sometimes an additional stage of search/replace (sed ftw!) to get there. great for monster log files
@b0rk I found Pup recently https://github.com/ericchiang/pup. It is described as Jq for HTML although I haven’t had a chance to try it myself yet.
@b0rk once i was working on a program that handled multitouch interactions on a screen, and we some bugs that were impossible to reproduce, resulting from touches/noise, we had a recorder/replayer for touches, but hadn't captured the bugs, i wrote some code to generate many many points in random locations on the screen, in the file format of the recorder. Once i discovered a bug with it, i would manually bisect the file until i had a short sequence of touches reproducing it, and start analysis.
@b0rk Calc/Excel, no kidding. They're great for quickly graphing the progression of trace data, latency histograms etc.
Trace - > grep/rg - > plaintext import or just ctrl-shift-alt-v - > (optional) massage data - > graph assistant.
Turning data into images is a powerful tool.
@b0rk That's a pretty broad category, I expect half of the tools in util-linux alone would fit into it.
@b0rk I use ksv for kaitai-struct described data. Not sure it fits the use case since it requires a format declaration, but it's pretty great! And the web IDE that implements it (https://ide.kaitai.io/) is very useful too.
@b0rk Can't forget the classics:
pipe into | base64, base32 etc.
grep, or if you feel like calling out/making some peeps remember the ancient times, make a separate entry for grep vs egrep
@b0rk strings is a good companion to hexdump/xxd for those use cases where you just want to extract and list text strings from a binary
@b0rk i used the SPIN model checker for some particularly nasty mulithreaded code. Model checkers are fuzzers, if you include the case where literally every possible input is tested. :)
@b0rk yes! i used afl and https://crates.io/crates/quickcheck to track down some tricky issues in my terminal parsing library
@b0rk it's more complex but i'm a fan of https://kaitai.io for visualizing binary files/structures; the github-hosted format library has parsers available for some well known file formats
@b0rk @dcrosta what difference do you make between fuzzing and PBT? I was under the impression that fuzzing was just the “does not crash” property.
I’ve used (and written) various PBT frameworks to great success, but will readily admit there’s a learning curve, and it takes a while to start writing useful properties that don’t basically reimplement the system under test
""" have any of you used a fuzzer for debugging? what specific fuzzing tool did you use?
- @b0rk
Disrupt the smooth flow of data in flight or at rest!
honestly, that's my most basic fuzzer - cut my Internet cable, or switch to Mobile Data from Wi Fi, or switch down to 2.4 GHz WiFi from 5 Ghz WiFi - delete a file, remove a dir - next tool is poke Nulls into Tables
# bots go boom
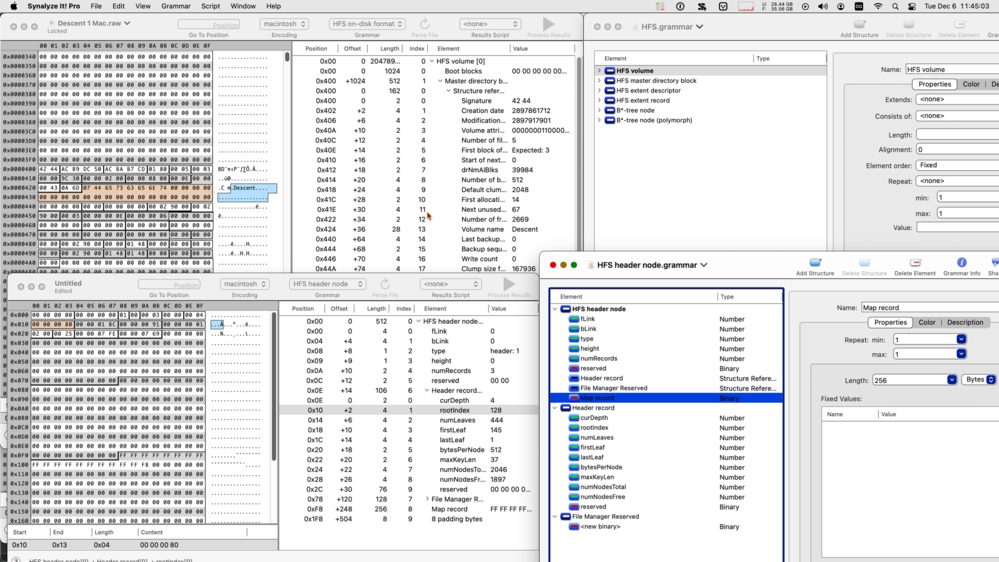
@b0rk I've been getting a lot of good use out of Synalyze It! lately. It's a hex editor with the ability to give it structure definitions (which it calls “grammars”) with which it can parse the bytes and show you the structures' values.
@b0rk have you seen Andrew Gallant’s CSV command line toolkit xsv? https://github.com/BurntSushi/xsv
On that note fuzzing-for-equivalence is similar: check that two functions are equivalent by fuzzing something that runs both and crashes on different results.
It is a subset of property testing, and the subset of property testing that's easy to implement as a fuzz target is larger than this, but I've found fuzzing-for-equivalent to be useful and to be a good way to think about property-testing-like things done in fuzz targets.
@b0rk I found xxd -i (generate C header) pretty magical when I wanted to embed a binary in a compiled executable.
@b0rk Less formatting, more selection and collating, but RecordStream is fantastically useful when you need to slice, map, reduce, etc., a bunch of records. Learning curve is somewhat steep unfortunately, but I've found it useful to have in my back pocket.
@b0rk not necessarily a fuzzer but I've reimplemented a few nontrivial algorithms in a different way and in those cases I simply generate random inputs and verify that both algorithms produce the same output - or in the case of floats, don't deviate too much. Put it in a loop and let it run a few minutes to be sure there is no bug (with a high degree of probability). This tends to catch bugs very quickly if they exist.
I guess that counts as property testing.
@b0rk pyplot, wireshark (also for non-network uses, for example it can decode chunks in png files)
Somewhat unrelated: tig, gitk, git blame (do you plan a section about studying the history of the code to find when a problem appeared? Both in practical terms (git bisect) and a more high level approach (how do we make sure this type of bug doesn't happen again?)
@b0rk, others have already mentioned the Octal Dumper aka od(1). It'll add that it is worth including simply for the legend/fact that the reason why keyword "do" is paired with "done" in Unix shell (as opposed to following the "if"-"fi" and "case"-"esac" pattern) is because od(1) was already a thing and actively used. Its options are quite odd (heh), but it's still in the POSIX, and there are people who prefer it to xxd and hexdump.
@b0rk zeek.org has a zeek-cut tool that works on their own TSV based formats.
They include a header in each file, and then the tool can output only the ones you need, but by name
$ cat dns.log | zeek-cut id.orig_h query answers
I have not seen that before, and only used in their software products
https://docs.zeek.org/en/master/log-formats.html
@b0rk I have used a related thing https://github.com/MozillaSecurity/lithium (and wrote scripts based on ddmin). When you hit bugs with a fuzzer you can use a test case reducer like this to isolate the input that caused it - but it works on bugs found in the wild too, in that case web pages/js that crash the browser.